2025年11月24日
ソフトウェア
AIファインチューニングの最適データ量ガイド|少なすぎても、多すぎても失敗する理由
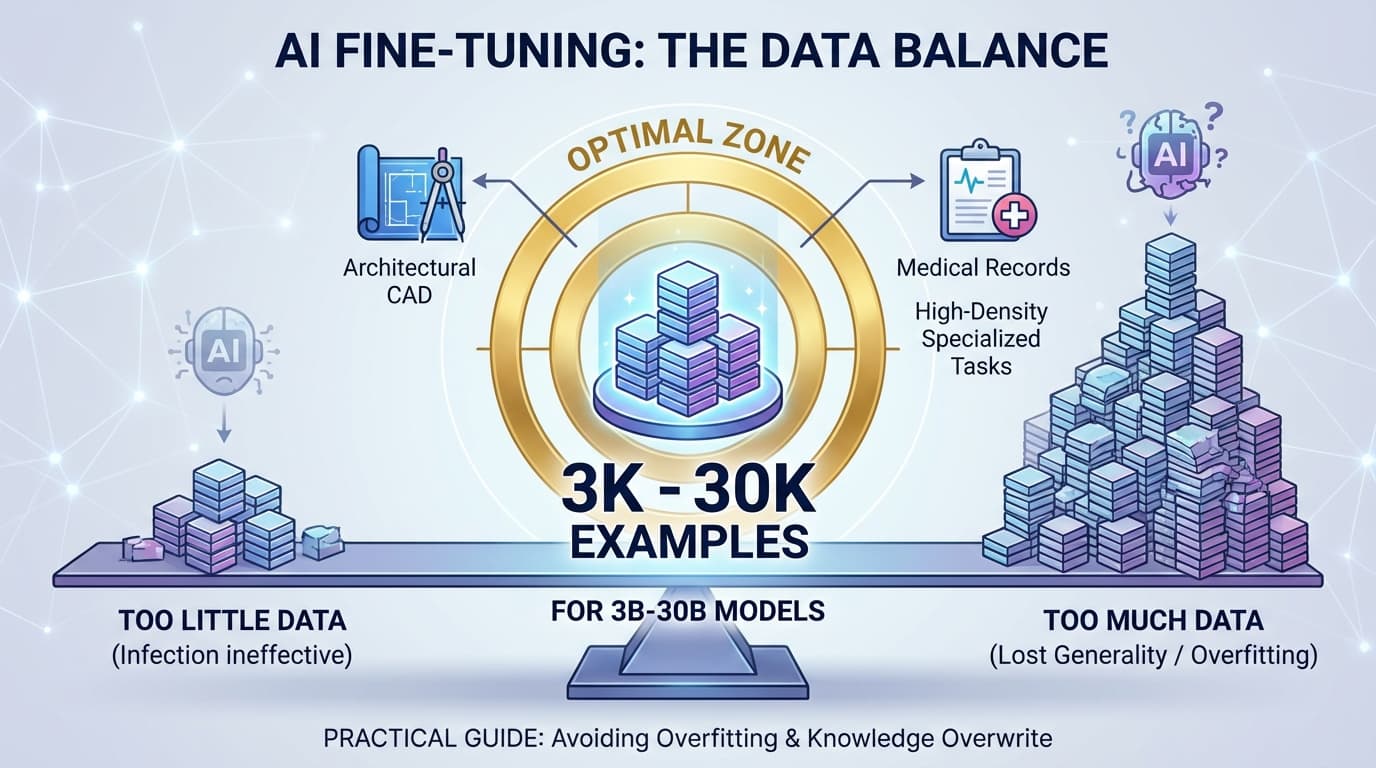
AIファインチューニングで「データは多ければ良い」というわけではない。少なすぎると効果が出ず、多すぎると汎用性が失われます。3B-30Bモデルでは3,000-30,000件が最適ゾーン。建築CADや医療記録など情報密度の高い専門タスクなら、この範囲で十分な効果を発揮。過学習と知識の上書きを避け、実用的なAIモデルを構築するための実践ガイドです。
AIファインチューニングの最適データ量ガイド|少なすぎても、多すぎても失敗する理由
はじめに:データ量が成否を分ける
「AIモデルのファインチューニングに、どのくらいのデータが必要ですか?」
これはAI導入を検討する企業から最もよく聞かれる質問の一つです。しかし、実は**「多ければ多いほど良い」わけではありません**。少なすぎても、多すぎても、モデルは期待通りに動作しなくなります。
本記事では、モデルサイズやタスクに応じた最適なデータ量、そして「データ量の罠」について、実務経験に基づいて解説します。
モデルサイズ別:必要データ量の目安
ファインチューニングに必要なデータ量は、モデルのパラメータ数によって大きく変わります。以下は、LoRA(低ランク適応)とフルファインチューニングの両方での目安です。
小規模モデル(1B〜7B)
| モデル規模 | 典型例 | LoRAの場合 | フルFTの場合 |
|---|---|---|---|
| 1B〜3B | Qwen2 1.5B, Llama3 2B | 1,000〜20,000件 | 10,000〜200,000件 |
| 7B | Llama3 8B, Qwen2.5 7B | 2,000〜50,000件 | 50,000〜500,000件 |
特徴
- 少量データでも学習効果が高い
- 特定タスクへの特化がしやすい
- 限られた計算リソースでも実行可能
中規模モデル(13B〜30B)
| モデル規模 | LoRAの場合 | フルFTの場合 |
|---|---|---|
| 13B | 5,000〜100,000件 | 100,000〜1,000,000件 |
| 30B | 20,000〜200,000件 | 200,000〜2,000,000件 |
特徴
- LoRAなら比較的少量でも効果が出る
- 専門分野への適応性が高い
- 過学習のリスクが低い
大規模モデル(70B以上)
| モデル規模 | LoRAの場合 | フルFTの場合 |
|---|---|---|
| 70B | 50,000〜300,000件 | 300,000〜3,000,000件 |
| 100B以上 | 100,000〜500,000件 | 500,000〜5,000,000件 |
特徴
- 基本的にLoRAのみで十分
- フルFTはコスト的に非現実的
- データ量よりも品質が重要
タスク別:必要なデータ量
同じモデルでも、タスクの複雑度によって必要なデータ量は変わります。
チャットスタイルの最適化(数百〜数千件)
用途例:カスタマーサポートの応答スタイル統一、敬語調整
小規模でも効果が出やすいタスクです。OpenAI形式のチューニングや、過去の対応ログを使った丁寧化などに適しています。
特定業務の手順化(数千〜数万件)
用途例:建築図面から部材一覧の抽出、見積補助、医療書式生成
RAGの代替として機能するレベルです。業務フローが明確な場合、この範囲で十分な精度が得られます。
高精度専門モデル化(数万〜数十万件)
用途例:法律文書生成、医療記録要約、CAD構造計算
ドメイン特化型モデルとして機能させるには、この規模が必要です。業界用語や専門的な推論パターンを学習させます。
コード生成・複雑推論(10万〜数百万件)
用途例:プログラミング支援、数式推論、マルチステップ推論
大規模モデルとフルファインチューニングがほぼ必須です。汎用性と専門性の両立が求められるタスクに適しています。
データ量と効果の関係
1,000件:変化が見え始める
LoRAであれば、モデルの出力に明確な変化が現れ始めます。ただし、まだ「実用レベル」とは言えません。
10,000件:ユーザーが違いを実感
一般的なタスクにおいて、ユーザーが「明らかに良くなった」と感じるレベルです。業務での実用に耐えうる品質になります。
50,000〜100,000件:専用モデルとして完成
タスク専用モデルとして十分な性能を発揮します。汎用LLMとは明確に異なる振る舞いをするようになります。
100,000件以上:別のモデルへ
元のベースモデルとは大きく異なる特性を持つようになります。専門性は高まりますが、汎用性は低下します。
危険ゾーン1:データが少なすぎる場合
① モデルが「例外扱い」してしまう
少量のデータでは、モデルは「これは特殊な例だな」と判断し、コアの振る舞いを維持します。結果として、期待したほど出力が変わりません。
② 表面的な癖だけを学ぶ
特に専門用語やスタイルチューニングでは、数百件程度だと「言い回しだけ変わったChatGPT」になってしまいます。JSON出力などの構造化タスクは特に不安定になります。
③ 過学習(Overfitting)
データが少ないのにepochsを回しすぎると、同じパターンを丸暗記してしまいます。新しい入力に対応できず、出力が硬直化します。
⚠️ 典型的な失敗例
JSON出力用に300件 → 出力フォーマットが揺れる
敬語調整に500件 → 一部だけ丁寧で全体的に不自然
建築図面抽出に800件 → 特定パターンしか認識できない
危険ゾーン2:データが多すぎる場合
① 元の知識を上書きしすぎる
大量データでの学習は、モデルの基礎能力を削ってしまいます。一般常識が弱くなり、通常タスクの性能が低下。チャットの自然さも失われます。
特に7B〜30Bクラスで顕著です。
② ノイズも一緒に学習してしまう
大量データには必ず含まれる誤字、曖昧な指示、矛盾したデータ、不均一な分布。これらがモデルの出力を不安定にし、「揺れ」を生み出します。
③ 偏りを強化してしまう
大量データに含まれる偏りが強く反映されます。ビジネス文書が極端に固くなったり、逆に軽すぎたり。人名・地名の推測が不自然になることもあります。
⚠️ 典型的な失敗例
100万件以上の学習 → 一般的な会話能力が壊れる
医療ログを詰め込みすぎ → 通常のQ&Aの多様性が消える
文体統一で大量投入 → 個性が死んで機械翻訳調になる
最適ゾーンの見極め方
現場でのチューニングでは、以下の指標で「適切なデータ量」を判断します。
✓ 意図した変化だけが出ているか
雑談能力や一般的なQ&A性能が劣化していないかを確認します。専門性を高めるために汎用性を犠牲にしていないか、バランスを見極めます。
✓ 出力の「揺れ」が増えていないか
同じプロンプトで毎回違う結果が出るようなら要注意です。過学習やノイズ過多の典型的なサインです。
✓ JSON構造化は安定か
構造化出力タスクでの安定性は、モデル全体の健全性を示す重要な指標です。ここが揺れると、他のタスクも不安定になっている可能性があります。
✓ Perplexityの変化
急落や急上昇は、過学習や知識の上書きを示唆します。適度な低下が理想的です。
実践的な推奨データ量
専門タスク向けの最適ライン
建築CAD、BOM抽出、医療記録構造化など、情報密度が高いタスクの場合:
3B〜8Bモデル
- 推奨:3,000〜10,000件
- この規模で十分な効果が得られる
14B〜30Bモデル
- 推奨:5,000〜30,000件
- これ以上増やすと「鈍く」なり、RAG的な文脈理解が弱まる傾向
💡 重要な注意点
10万件を超えると、専門性は高まるものの、柔軟性と汎用性が大きく損なわれます。業務での実用性を考えると、3,000〜30,000件の範囲で調整するのが最も現実的です。
まとめ:最適データ量は「質×量×モデルサイズ」で決まる
ファインチューニングの成功は、単にデータを多く集めれば良いわけではありません。
重要なポイント
- モデルサイズに応じた適切な範囲がある
- タスクの複雑度によって必要量は変わる
- 少なすぎると変化が出ない、多すぎると別のモデルになる
- 最適ゾーンは「3,000〜50,000件」(LoRA、中小規模モデル)
- データの質が量よりも重要な場合も多い
次のステップ
もしファインチューニングを検討されている場合は、まず以下を明確にしましょう:
- 使用するモデルのサイズ
- 達成したいタスクの具体的な内容
- 現在収集可能なデータの量と質
適切なデータ量の見積もりと、効果的なファインチューニング戦略について、専門家に相談することをお勧めします。
関連記事
- RAG vs ファインチューニング:どちらを選ぶべきか
- LoRAによる効率的なモデルカスタマイズ入門
- 中小企業が取り組めるAI活用の現実的なアプローチ
