AI×データ連携 実装ノウハウ
AIを実装するための最新ノウハウと活用事例を発信しています
33件の記事が見つかりました(1 / 2ページ)

ハードウェア
ASUS Ascent GX10(NVIDIA GB10 / DGX Spark)を使ってみた感想
ASUS Ascent GX10(NVIDIA GB10)を実機検証。273GB/sの帯域制約とMoEモデルによる多接続・高精度の両立方法、Ollama vs vLLMの使い分けを解説。
生成AI

技術情報
データ連携時のPythonでの定義方法と渡し方
pydanticを中心とした型定義、dictとモデルの使い分け、async環境での渡し方など、データ連携 Pythonコードの実装指針を整理。境界で型確定、内部はdictで柔軟に。
DX

ソフトウェア
n8nの始め方と限界 ― 業務自動化を現場に定着させるには
n8nのセットアップから実用ワークフロー作成までを解説。日本主要SaaS連携・大量データ・ローカルLLM・承認フローでの限界とDigitalBaseとの比較。
DX

AI
LLM I/Oとデータ連携基盤の相性のいい作り方
LLMとデータ連携基盤の境界設計を整理。構造化出力・冪等性・スキーマ駆動・観測可能性の4原則と実装パターンを解説。
生成AI

AI
VLM(画像言語モデル)での図面読み取り精度検証
Qwen3.5系VLMを使ったCAD図面・手書き図面の読み取り精度を完全オフライン環境で検証。前処理・プロンプト・段階処理の設計指針と運用に向けた組み込み方法を解説。
生成AI

インフラ
Ubuntu構築から社内LAN接続、ケーブル直結利用まで ― AIサーバーを「現場で使える」状態にする
Ubuntu 24.04 LTSのAIサーバー構築手順。Avahi(mDNS)とリンクローカルIP固定でケーブル直結対応を実現し、ネットワーク管理者不要で現場展開できる状態を作る方法をまとめる。

技術情報
Cron + Webhookで業務フローを組む実例
CronとWebhookを組み合わせた業務フロー自動化の5パターンを実装者目線で解説。AI自動処理を含む現実的な構成を紹介。
DX生成AI
AI
オープンソースでLLM構築 | OllamaからvLLMへのマイグレーションで複数モデル同時利用
ローカルLLM推論エンジンとして広く使われている
組み込み

インフラ
CUDA環境構築のベストプラクティス | ベアメタル・Docker・VMの構造比較と最適な選び方
GPU を使った AI 推論や LLM の稼働環境を構築する際、「とりあえず Docker で」と考えるエンジニアは多い。しかし CUDA と Docker の組み合わせは、CPU ベースのアプリケーションとは根本的に異なる課題を抱えている。この記事では、CUDA 環境を Docker で構築する際にハマりやすいポイントを整理し、ベアメタル・Docker・VM それぞれの構造的な違いと、ユースケース別の最適解を解説する。
生成AI

RAG
pgvectorのメリットと実践構築方法
RAG実装に専用Vector DB。PostgreSQLの拡張機能pgvectorを使えば、既存のデータベースでベクトル検索が可能に。SQLAlchemy + Pydanticで型安全な実装ができ、通常のテーブルとJOINも自由自在。インフラ追加なし、コスト削減、運用シンプル化を実現する実践的な構築方法を解説します。
生成AI

RAG
RAG実装におけるベクトルインデックス:HNSWとIVFFlatの比較と活用ガイド
RAG(Retrieval-Augmented Generation)を本番環境で運用する際、ベクトル検索のパフォーマンスを左右するのがインデックスの選択です。現在、主要なベクトルインデックスとして
生成AI

技術情報
LLMファインチューニングを成功させるデータセット設計の実践ガイド
ファインチューニングの成功を決定づけるのはデータの量ではなく質です。500〜1,000件の高品質なデータが5万件の低品質データを上回る性能を発揮します。本ガイドでは、データセットの品質特性、効果的なフォーマット選択、PEFTとLoRAによるデータ効率化、ドメイン特化型設計、日本語LLMの実践事例、合成データ生成、避けるべき落とし穴まで、実務で即活用できる知見を体系的に解説します。
生成AI最新情報

ハードウェア
ローカルLLM選定ポイント: MoEモデルについてGPTOSS 20BとGemma 3 12Bを元に比較
ローカルLLM導入を検討する際、MoE(Mixture of Experts)モデル(gpt-ossなど)の導入を検討された方向けに、通常モデルとの比較をしました。GPT-OSS-20B(MoE)とGemma 3 12Bの比較を通じて、アーキテクチャの違い、性能特性、ビジネス用途での選び方を徹底的に解説しています。
生成AI調査

ハードウェア
Ollama向けファインチューニング比較: ChatML形式, Gemma形式, Llama形式の差分を解説
Ollamaのファインチューニングにおいて、チャットテンプレートの選択は成否を分ける重要な要素だ。テンプレートが学習時と推論時で一致しないと、モデルは期待通りの出力を返さない。本記事では、主要な3形式(ChatML・Gemma・Llama)の構文を比較し、実装上の注意点を解説。
生成AI

RAG
RAG実装における次元の設定方法 | 768d vs 1536d vs 3072d
RAG(Retrieval-Augmented Generation)システムを構築する際、Embeddingの次元数は、検索精度、ストレージコスト、検索速度に直接影響する重要なパラメータです。本記事では、768次元、1536次元、3072次元の実装上の違いと、ビジネス要件に応じた最適な選択方法を解説します。
生成AI

RAG
RAG構築: OpenAIとOllamaでの構築の違いと注意点
RAG(Retrieval-Augmented Generation)システムを構築する際、Embeddingモデルの選択は、システムの性能、コスト、運用体制に大きな影響を与える重要な意思決定です。本記事では、OpenAI APIとOllama(ローカルLLM)それぞれでRAGを構築する際の実装上の違いと、実際のプロダクション環境で直面する課題について解説します。
生成AI組み込み

ハードウェア
LLM向けファインチューニング解説: ChatML形式とAlpaca形式を比較
LLMファインチューニングには主にAlpaca形式とChatML形式の2つのデータフォーマットが存在します。それぞれの歴史的背景、データ構造の違い、性能特性を解説し、Unslothでの実装方法を紹介。どちらの形式を選ぶべきかの判断基準も示します。
生成AI組み込み

ソフトウェア
GitHub Actions: macos-latestでのビルドの注意点
GitHub Actionsを使ってmacOS向けのバイナリをビルドしている開発者の方へ。「ローカルでは動くのに、CI/CDでビルドしたバイナリが動かない」という問題に遭遇したことはありませんか?
本記事では、
組み込み
ソフトウェア
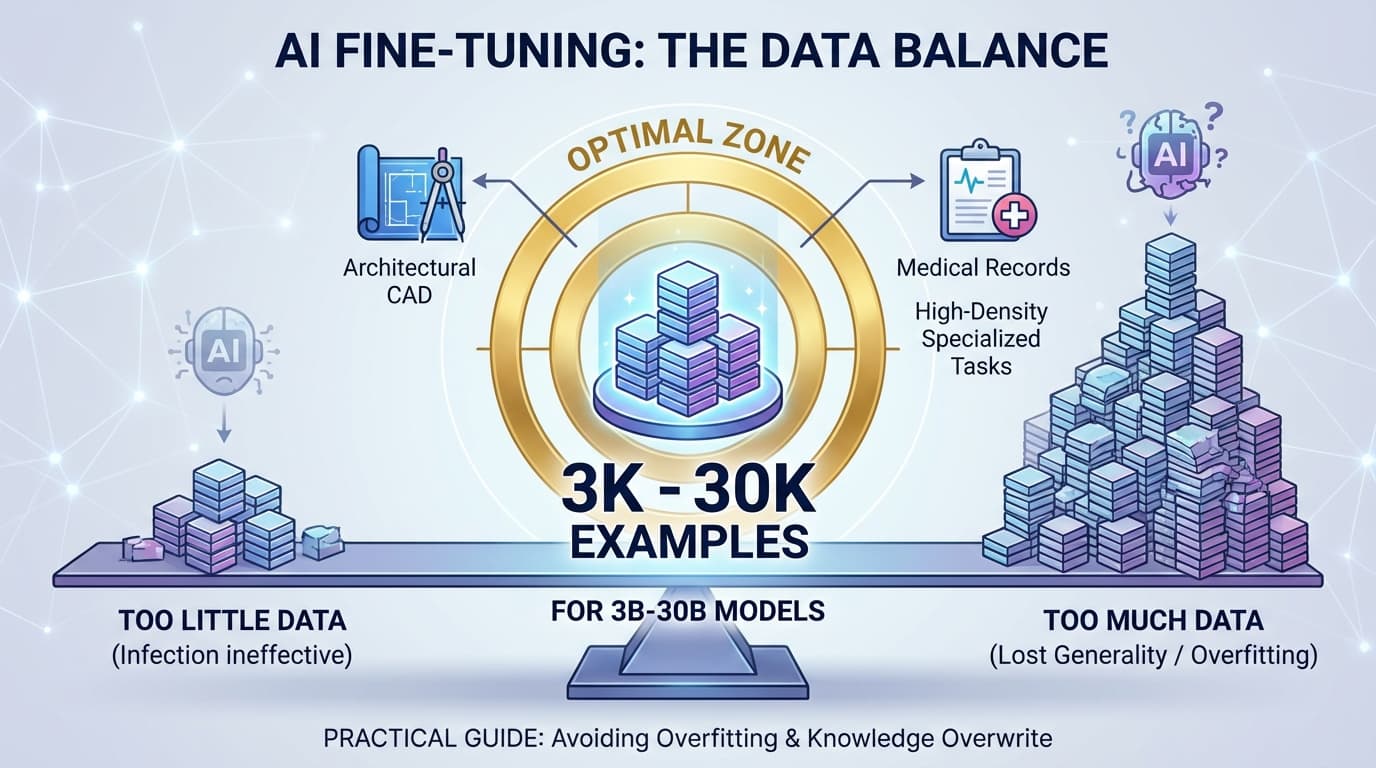
AIファインチューニングの最適データ量ガイド|少なすぎても、多すぎても失敗する理由
AIファインチューニングで「データは多ければ良い」というわけではない。少なすぎると効果が出ず、多すぎると汎用性が失われます。3B-30Bモデルでは3,000-30,000件が最適ゾーン。建築CADや医療記録など情報密度の高い専門タスクなら、この範囲で十分な効果を発揮。過学習と知識の上書きを避け、実用的なAIモデルを構築するための実践ガイドです。
生成AI

ハードウェア
AI構築ノウハウ: Docker, ベアメタル, WSLの環境差分を比較してみた
AI構築でのベアメタル、Docker、WSL2を実務経験から徹底比較。GPU性能では差が少ないが、ファイルI/OではWSLのWindowsドライブ経由が10倍以上遅い。迷ったらDockerが最適解。本番環境はベアメタル、開発はDocker、Windows個人開発はWSL2が推奨。ユースケース別の選択基準と実測データで最適環境を提案します。

技術情報
社内LANで実現する安全なAI開発環境
社内LANを活用することで、開発中のアプリケーションやサービスを外部に公開せずに安全に共有できる。WANとLANの違い、ルーターのポートフォワーディング、0.0.0.0バインディング、有線・Wi-Fiの使い分けを解説。
DX