オンプレAIエージェント基盤 DigitalBase
AIエージェント・ワークフロー・RAG・推論サーバー管理までを1つに。 社内データベース・ファイル・業務システムをオンプレのままAIに繋ぎ、業務に組み込んで動かす基盤です。
- AIエージェントが検索・SQL・コード実行・ツール連携まで実行(Tool Calling・MCP)
- 完全オフライン稼働・AD連携・3階層権限・監査ログを標準装備
- vLLM のモデル管理まで、情シスが運用できる本番基盤



画面イメージ
AIエージェント基盤で分析・資料作成など様々な業務に適用
小さく始めて、業務全体へ。まずは現場で効く3つの仕事から導入できます。
分析
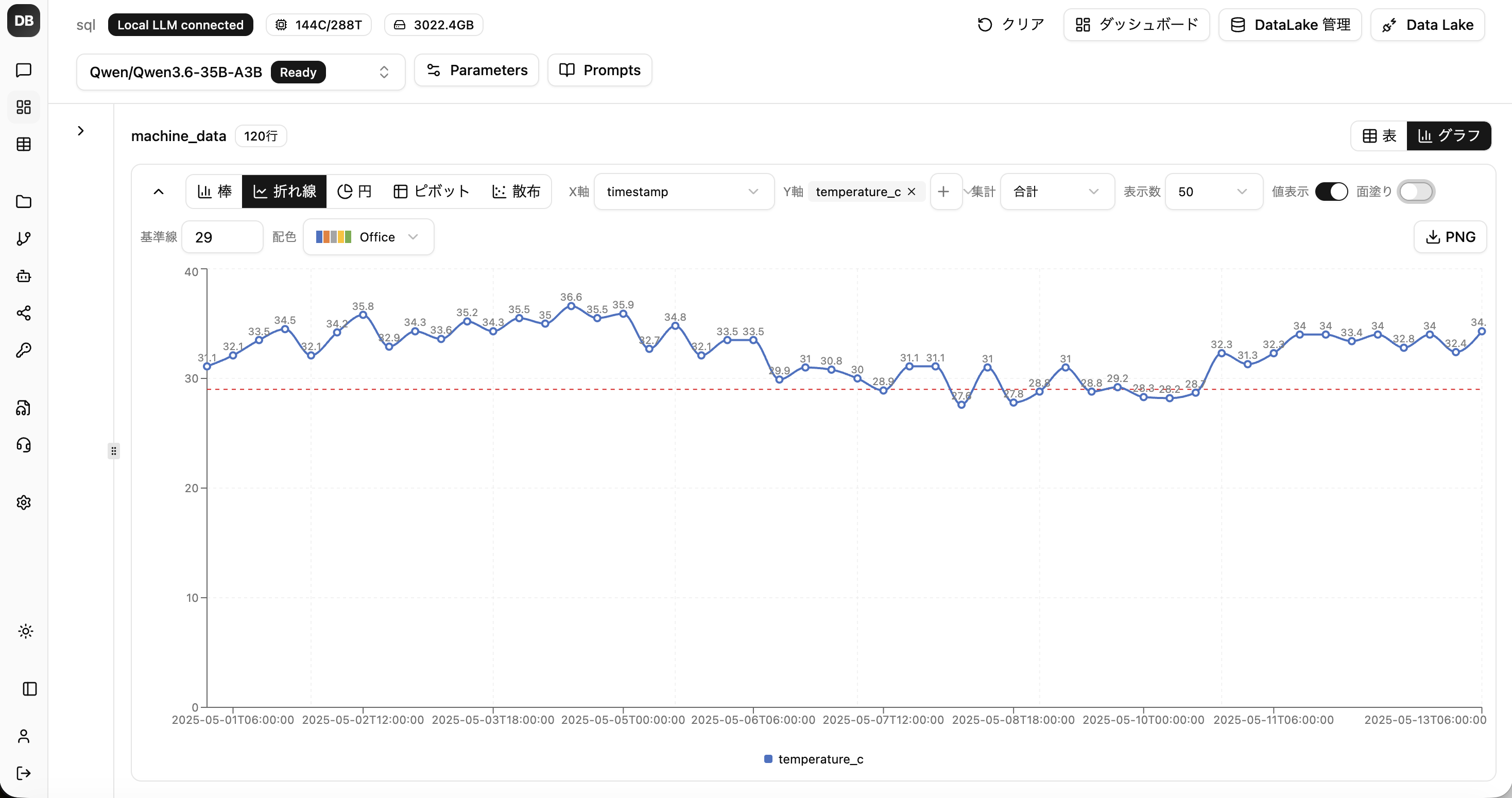
自然文で、社内データを集計・可視化
SQLエージェントが社内DBに問い合わせ、集計から可視化までを自動化。専門知識がなくても、必要な数字をその場で引き出せます。
- 自然文で問い合わせ.
- 質問を投げると、AIがSQLを生成してデータを取得。
- ダッシュボード化.
- 結果をチャート化し、複数チャートのダッシュボードに。
- 横断検索.
- 社内文書も RAG で横断的に検索・参照。
図面・帳票の読取
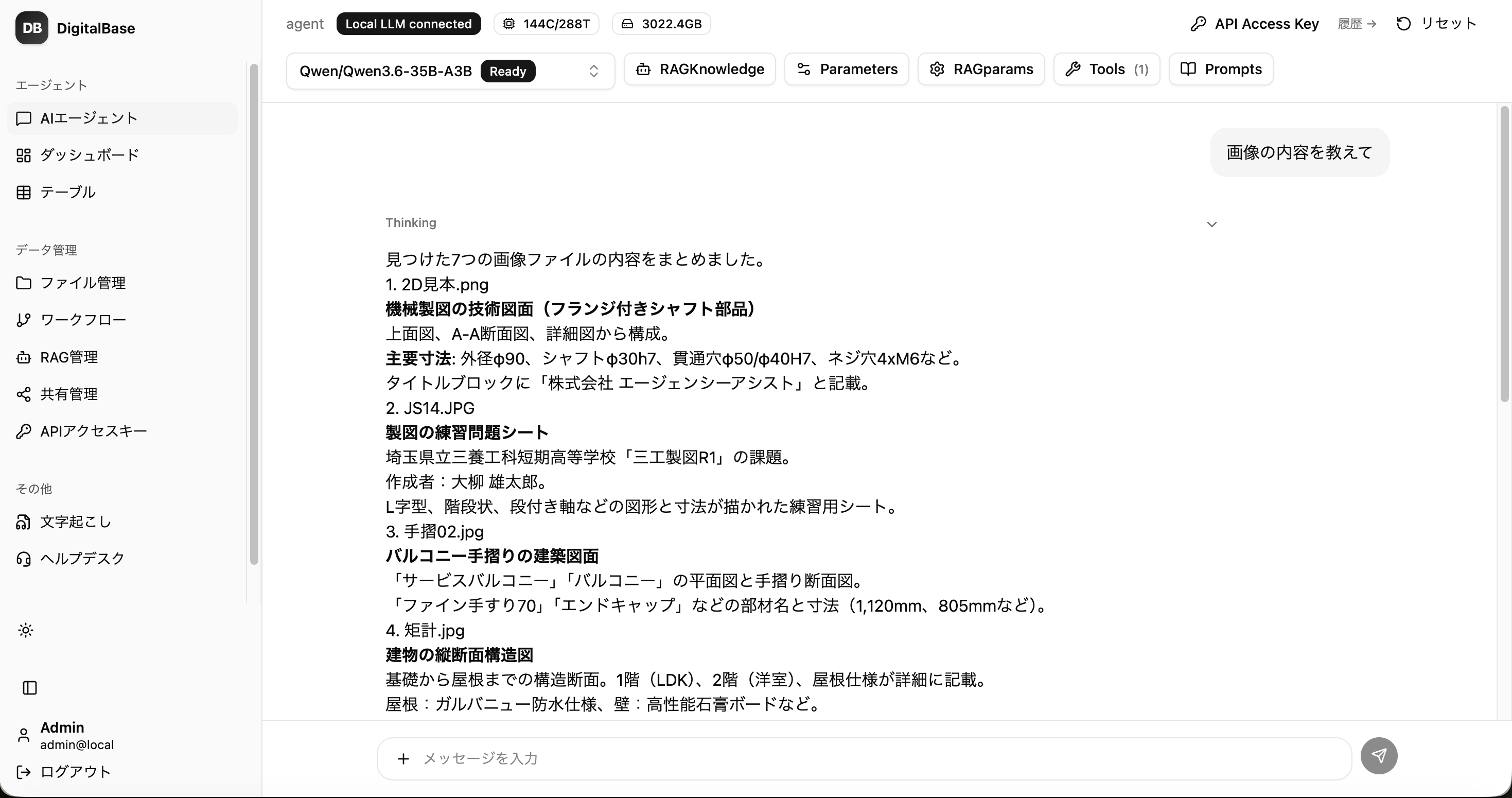
図面・帳票・写真を、AIが読み取る
VLM/OCR で、図面・帳票・現場写真から必要な項目を抽出。読み取った内容を構造化し、データベースに登録するところまで自動化します。
- VLMで項目抽出.
- 図面や帳票から、AIが必要な項目を読み取り。
- OCRにも対応.
- スキャン文書・手書きにもフォールバックで対応。
- 構造化してDBへ.
- 抽出結果をそのままデータベース/RAGに蓄積。
資料作成
社内データから、資料をAIが作成
社内データやテンプレートを元に、報告書・提案書・各種文書をAIが生成。オンプレ環境のまま、作成から配布までを自動化します。
- データ参照で生成.
- 社内データを根拠に、AIが文書を執筆。
- テンプレート対応.
- 既定のフォーマットに沿って出力。
- 配布まで自動.
- 生成→保存→メール配布までフロー化。
AIエージェント
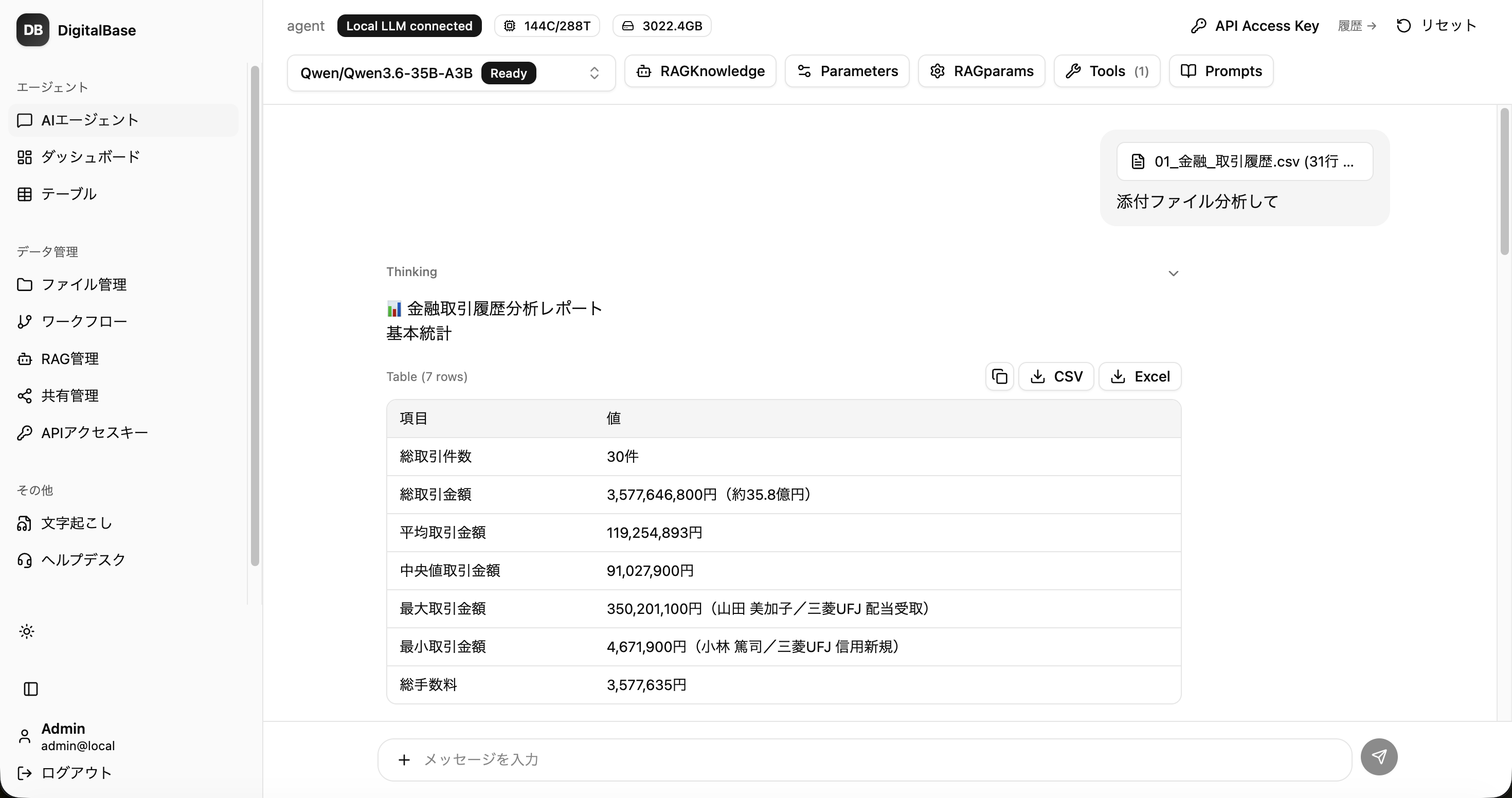
対話するだけで、AIが業務をこなす
チャットから指示するだけ。AIが検索・SQL・コード実行・ツール呼び出しまで行い、「聞いて答える」で終わらず、業務そのものを進めます。
- ツール実行.
- ファイル操作・SQL・コード実行・社内システム呼び出しをAIが実施。
- 出典つき検索.
- 社内文書(RAG)を根拠に、出典つきで回答。
- 対応モデル自由.
- ローカルLLM(Qwen等)からクラウドまで切替可能。
ワークフロー
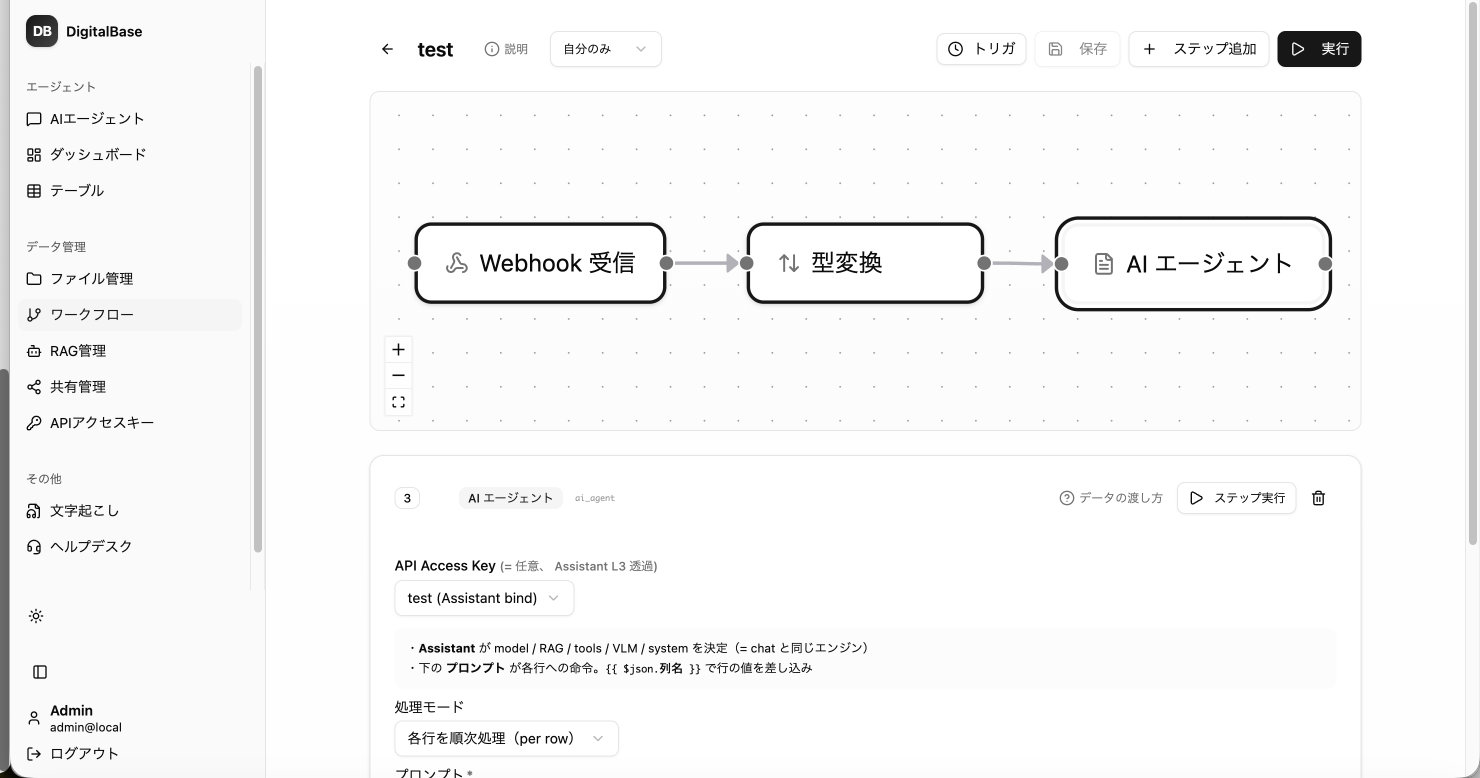
取込から連携まで、自動で回す
ノーコードのパイプラインで、データ取込・AI処理・分岐・通知・書き戻しを自動実行。cron・Webhook で定期・常時の自動化も。
- ノーコード構築.
- 画面上でステップを繋ぐだけ。80以上の部品を組み合わせ。
- 分岐・条件処理.
- 条件分岐・ループで、複雑な業務フローも自動化。
- 定期・常時実行.
- cron / Webhook で、無人で回し続ける。
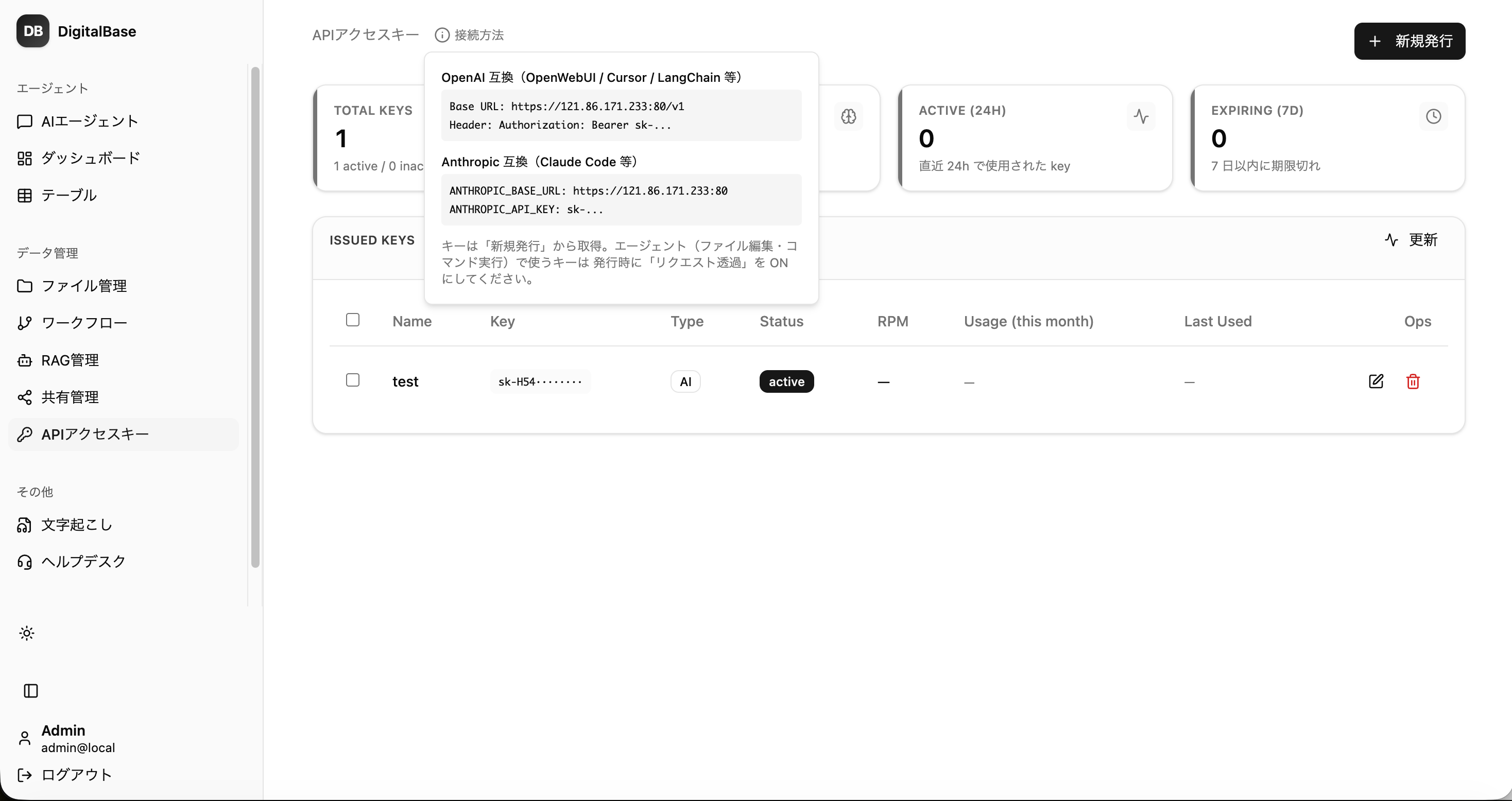
API連携
既存ツールも、そのまま接続
APIキーで OpenAI互換・MCP エンドポイントを発行。Claude Code・Cursor・OpenWebUI など既存資産を、データを外に出さず・統制下で、そのまま動かせます。
- OpenAI / Anthropic 互換.
- コード変更ゼロで、既存ツールがそのまま刺さる。
- MCP対応.
- Claude Code・Cursor から社内ツールを呼び出し。
- キー単位の統制.
- 発行キーごとに権限・利用量・IP制限を管理。
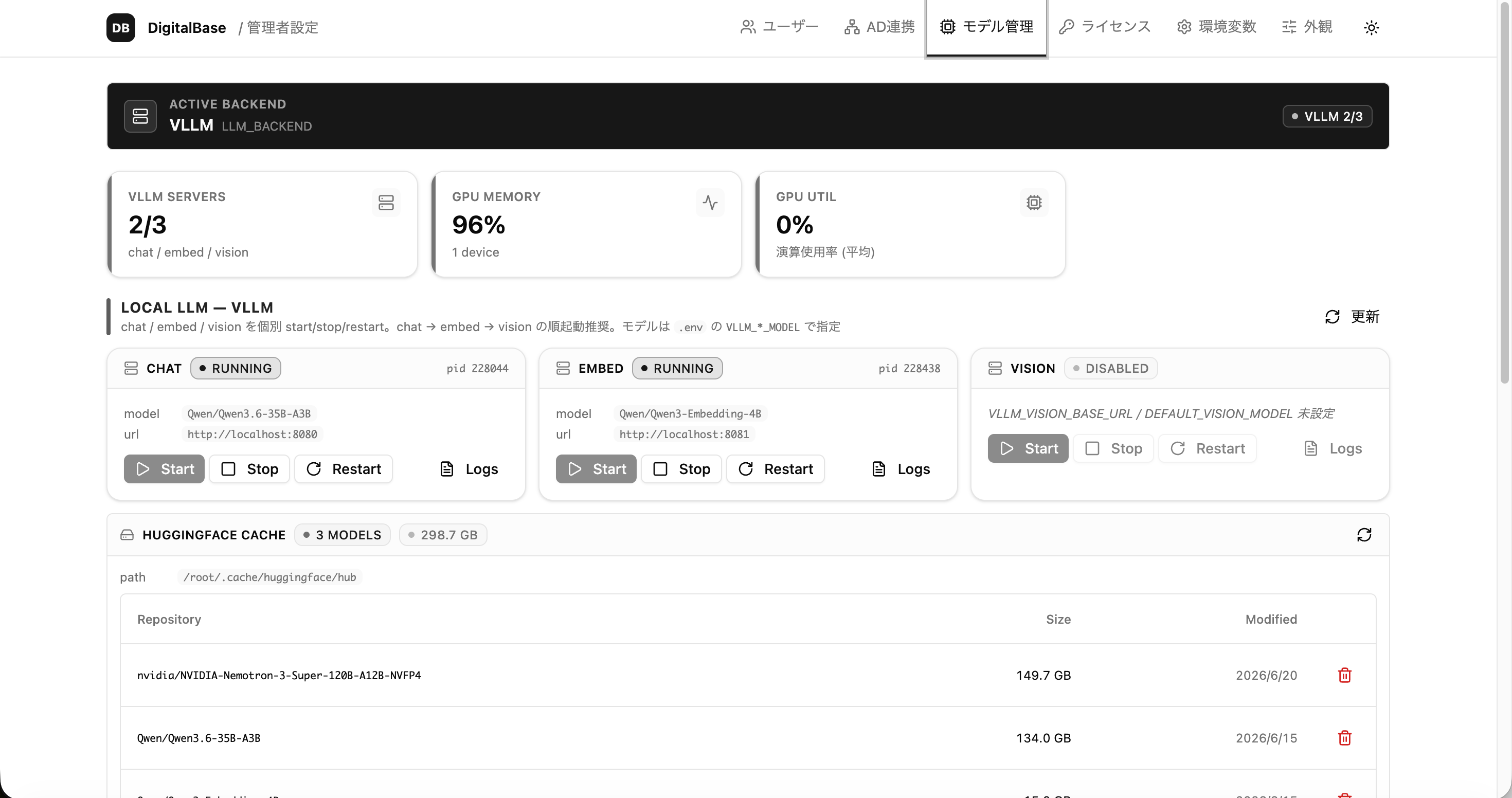
推論サーバー管理
vLLMまで、管理画面から運用
AI推論サーバー(vLLM)の chat / embed / vision を、管理画面から起動・管理。GPU監視、モデル導入・切替まで、情シスが本番運用できます。
- サーバー起動・管理.
- chat / embed / vision を個別に start / stop / restart。
- モデル導入・切替.
- Qwen・NVIDIA Nemotron 等をサーバーに導入。
- GPU・稼働監視.
- GPU使用率・サーバー状態を画面で確認。
機能一覧
実際にご利用をいただける機能一覧
必要な機能を選んで組み合わせ、1つの基盤に集約。すべて追加課金なしで同梱します。
ユーザー機能
- AIエージェント
- 対話しながら資料作成・検索・タスク実行。ツールを呼び出して業務をこなす。
- ダッシュボード
- SQLで集計・可視化し、稼働状況を管理。
- テーブル
- 画面上でデータを修正・編集し、DBへ書き戻し。
- ファイル管理
- エージェントが使うデータを整理・供給する下地。
- ワークフロー
- パイプラインを自動・定期実行(cron・Webhook)。
- RAG管理
- 社内文書を登録し、出典付き回答の土台に。
- 共有管理
- タグ単位でボット・パイプラインをチーム共有。
- APIアクセスキー
- OpenAI互換・MCPで、既存ツールやClaude Codeを接続。
- 文字起こし
- 会議音声などをテキスト化し、要約・活用。
- ヘルプデスク
- 問い合わせ対応をルーム単位で管理。
管理者機能
- AD連携・SSO
- Active Directory / LDAP・OIDC と統合、3階層権限。
- モデル管理
- vLLM の chat/embed/vision を個別に起動・管理。GPU監視・モデル導入も画面から。
- 利用者・ライセンス管理
- ユーザー・ロール・席数・監査ログを一元管理。
- UI調整
- ロゴ・配色・サイドバー・既定モデルをカスタマイズ。
エンタープライズ対応
推論サーバーまで、情シスが運用できる
認証・監査・データ保護に加え、AI推論サーバー(vLLM)の管理までを標準装備。 情報システム部門の審査を通す要件を、オンプレミス環境で満たします。
管理画面:AI推論サーバー(vLLM)の chat / embed / vision を起動・管理、GPU・モデルを監視
認証・アクセス管理
AD / LDAP 連携
既存のActive Directory・LDAPと統合。属性・グループも取り込み。
SSO / OIDC
Microsoft Entra ID 等のOIDCプロバイダでシングルサインオン。
3階層の権限管理
SUPER / ADMIN / USER のロールでアクセスを細かく制御。
監査・ガバナンス
監査ログ
誰がいつ何をしたかを記録。ログイン・操作・実行を追跡。
利用ダッシュボード
利用状況・処理件数・エラー率をリアルタイムで可視化。
シャドーAI防止
AI利用を統合管理し、許可外の野良AI利用を抑止。
推論サーバー・運用
推論サーバー管理
vLLM の chat / embed / vision を画面から起動・管理、GPU使用率を監視。
モデル管理
Qwen・NVIDIA Nemotron 等を、サーバーに導入・切替。
デプロイ
Docker / Kubernetes・完全オフライン・マルチアーキに対応。
データ保護
社内ネットワーク完結
データを社内に置いたまま処理。外部送信ゼロを選択可能。
オンプレDBで保持
PostgreSQL+pgvectorで、文書もベクトルも社内に保持。
ソースコード保護
実行バイナリはコンパイル済みで、知的財産を保護。
連携済み構築環境
検証から本番まで、連携済みの環境で構築・運用
DigitalBase は、クラウド・GPUサーバ・ネットワーク・エッジまで、各社の環境と連携済み。 検証から全社展開・保守運用まで、各フェーズに最適な環境で構築できます。







世界の分散拠点でGPUインスタンスを提供。低コスト・低遅延で PoC・効果検証を実施できます。
NVIDIA H100 / H200 / B200 / GB200 のGPUクラウド。NVIDIA Cloud Partner として最新GPUを確保。
ThinkSystem SR675 / SR680a(HGX H100・H200 8GPU)等の、オンプレGPUサーバ・WSを提供。
ソニーグループ。エッジAIアプリの実行基盤(Edge App Runtime)で、分散・エッジ運用を支援。
台湾のエッジAI企業。外観検査AI(AINavi)やエンタープライズLLM基盤(EdgeStar)を展開。
GPUクラウド WebARENA IndigoGPU(H100/H200/B200・8GPU)。NVIDIAエリートパートナー、Innovation LAB 認定。
関西電力グループ。GMI Cloud と提携し日本リージョンで GPU(B200)を提供。回線・DCを保有。
※ 連携内容・カバレッジは各社との協業内容に基づきます。提携内容は予告なく変更される場合があります。
下記お悩みをお持ちの方は是非ご相談ください
社内データを安全にAIに連携できます
AIを導入したが、社内データと繋がっていないため活用されない
クリックして解決策を見る →
既存データをそのままAIに接続して業務で活用できます
- DB・Excel・PDF・画像など既存データソースをそのままAIに接続
- パイプラインでデータの取り込み・変換・出力を自動化
- 業務フローに組み込むことで、AIがPoCで終わらず定着する
セキュリティ基準でクラウドAIに社内データを渡せない
クリックして解決策を見る →
データを外に出さず、社内環境だけで完結します
- データ外部送信ゼロ。AI処理を含めて社内ネットワーク内で完結
- AD連携対応。既存のユーザー・権限管理をそのまま引き継げる
- 利用ログ・アクセス履歴を記録。監査・コンプライアンス対応も可能
AI基盤を導入したいが、社内のエンジニア人員が限られている
クリックして解決策を見る →
標準化された導入プロセスとパートナー網で支援します
- Lenovo / NVIDIA / NTTPC と連携した標準パッケージで構築を効率化
- 必要なAI機能と業務機能をモジュールとして組み合わせて提供
- 導入後は事業部の担当者でも運用可能な管理画面を標準装備
社員が個別にAIツールを使い始め、管理できない(シャドーAI問題)
クリックして解決策を見る →
GPU・モデル・権限・ログを統合管理し、シャドーAIを防ぎます
- 誰が・いつ・どのデータで・何をAIに聞いたかを利用ログで記録
- 部署・役職ごとのアクセス権限を一元管理。機密データへの不正アクセスを防止
- 承認されたAI環境のみを社内に展開し、個別ツールの乱立を防止
社内データが拠点・部署ごとにバラバラで集約できていない
クリックして解決策を見る →
パイプラインでデータを自動取り込み・変換・統合できます
- CSV・Excel・REST API・SQLデータベースなど多様なデータソースに対応
- AIがフォーマット差異を吸収し、統一スキーマに自動変換
- スケジュール実行で定期的にデータを自動同期。手動集計が不要に
GPUサーバーの構築・運用が難しく、AI環境を整備できない
クリックして解決策を見る →
マルチGPU対応で、ハードウェアの最適化もサポートします
- NVIDIA/Intel GPU対応。ハードウェアに最適化された軽量設計で小型PCでも稼働
- モデル選定・パラメータ調整・ベンチマーク測定機能を搭載
- EdgeStar等のAI専用サーバーとの連携実績あり
既存の業務システムを変えずにAIを組み込みたい
クリックして解決策を見る →
REST API連携とWebhookで既存システムとAIを安全に接続します
- 既存のデータベースをそのままの場所に置いたままAIに接続。データ移行不要
- Webhook・REST APIで外部システムとの双方向連携が可能
- 承認フロー・自動通知で業務プロセスにAIを直接組み込める
AI導入の効果が見えず、経営層への説明が難しい
クリックして解決策を見る →
ダッシュボードでAI活用状況と業務改善効果を可視化します
- パイプラインの実行回数・処理件数・エラー率をリアルタイム表示
- 部署ごとのAI利用状況を集計。活用率の低い部門を特定して改善
- 削減工数・処理時間短縮などの定量データを経営報告用にエクスポート可能
AI導入の進め方
個人利用から全社展開まで、段階的に導入できます
個人・部署で試験
デスクトップPC
まずは個人や小チームで試験的に利用開始
チームで検証
社内サーバー
効果を確認しながらチームに展開、パラメータを調整
全社展開
業務に定着
社内全体でAIを活用し、業務フローに組み込む
継続的な改善
最適化・進化
データを蓄積し、自社専用AIとして継続的に進化
PC・サーバー・クラウドまで、用途やセキュリティ要件に合わせて構築できます
ハードウェア構築プラン
利用人数・用途・セキュリティ要件に応じて、4段階の構成をご用意しています
デスクトップ  | DGX SPARK  | ワークステーション  | ラックサーバ  | |
|---|---|---|---|---|
| 構成 | Intel Core ミニPC / 小規模サーバ | NVIDIA製 小型スパコン | NVIDIA RTX PRO 6000 Blackwell Max-Q ×2〜4枚 | NVIDIA RTX PRO 6000 Blackwell ×8枚〜 |
| モデルサイズ | 3B〜8B | 30B〜70B(MoE推奨) ※帯域273GB/sのためMoE推奨 | 70B〜200B | 200B〜400B |
| 目安人数 | 数名規模・部門小チーム | 5〜20人程度 | 20〜50人程度 | 50〜100人以上 |
| 用途 |
|
|
|
|
| インフラ管理 |
|
|
|
|
| 対応AI機能 |
|
|
|
|
| 推論エンジン | Ollama / クラウドLLM | Ollama / vLLM / クラウドLLM | vLLM / クラウドLLM | vLLM / 複数並列 |
| HW詳細 ※構成・世代により変動の可能性 | CPU: Intel Core Ultra 系 RAM: 32GB / 64GB サイズ: ノートPC / ミニPC(112×144×42mm 程度) | GPU: NVIDIA GB10 (Grace Blackwell) 統合メモリ: 128GB LPDDR5X 帯域: 273GB/s サイズ: 150×150×51mm | GPU: RTX PRO 6000 Blackwell Max-Q ×2〜4 VRAM: 192〜384GB (96GB×N) 帯域: 1.8TB/s/枚 サイズ: タワー型(約 165×450×550mm) | GPU: RTX PRO 6000 Blackwell ×8〜 VRAM: 768GB〜 帯域: 1.8TB/s/枚 筐体: 4U〜ラックマウント |
導入の流れ
ご要件のヒアリングから本番運用まで段階的に進めます
まずはお気軽にご相談ください
社内データをAIに繋げたい、情シス審査を通せるAI基盤を探しているなど、お気軽にご相談ください。
お問い合わせ
ご質問やご相談など、お気軽にお問い合わせください。
デジタルベース株式会社
〒106-0047
東京都港区南麻布3-20-1 5階
お問い合わせ
NVIDIA Inception Program / Intel Partner ISV /
NTTPC Innovation LAB / IT導入補助金 対象